Build a Stock Screener with Python (Part 3): Working with CSV Files
Let's get our data into CSV/Excel! Final GitHub Repo.
Final output:
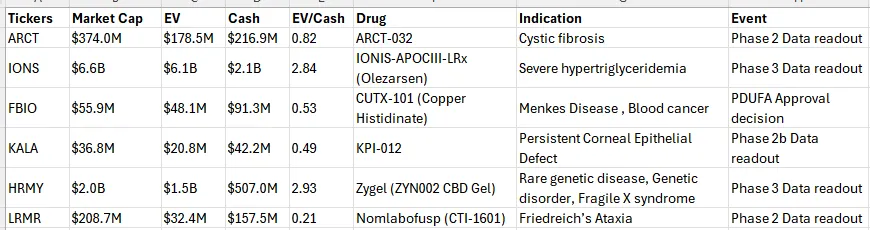
In Part 2, we pulled biotech catalyst data into our stock screener using the BPIQ API. Up to this point we display the stock screener in our terminal. It would be more useful if we could save the data for future reference. In this walkthrough (Part 3) that's what we'll do.
We will read in data from a csv file and write/export our stock screener data to a separate CSV/Excel file..
If you haven't seen Part 2 (or Part 1), check them out. They are quick and will get you up to speed. However, you can grab the base code from GitHub and follow along starting from this Part 3 exercise.
Overview of Steps:
- Create a CSV file with tickers of interest.
- Update our main() function to ingest these tickers.
- Update our get_catalyst_data() function to get BPIQ Big Movers.
- Update our main() function to write our data to a csv file.
Creating a csv file with tickers of interest:
In Part 1 and Part 2 we read in tickers from a .txt file, but who uses .txt files? (I'll admit I sometimes do for quick notes - tisk, tisk). You probably store your stock portfolio in csv/excel files (hopefully G-Sheets).
- First, create a new file in your project directory 'tickers.csv' and add in a row for each ticker and company name. Here is my example:
ticker, company
ARCT, Arcturus Tx
IONS, Ionis Pharma
FBIO, Fortress Bio
KALA, Kala Bio
HRMY, Harmony Bio
LRMR, Larimar Tx
Updating our main() function to ingest these tickers.
- Let's update our main() function to read the tickers in from the csv file instead of the txt file:
- First we want to import a built in python module 'csv' to handle interacting with our csv files, so at the top add:
import csv # <== NEW FROM PART 2
from datetime import date, timedelta
... # prev imports below
- Next update the main() function to open the csv, read it into a DictReader object that is iterable and stores each row in a dictionary using the column header as the key. We need to also update the calls to the other functions to pass in the ticker:
def main():
# with open("tickers.txt") as f:
# tickers = [line.strip().upper() for line in f if line.strip()]
# NEW ====
with open("tickers.csv", "r") as file:
# creates an iterable object with a dictionary for each row using the headers as the key
reader = csv.DictReader(file)
ticker_data_list = []
for row in reader:
print(row)
ticker_data_list.append(row)
results = []
for ticker_dict in ticker_data_list: # <=== UPDATE
data = get_stock_data(ticker_dict["ticker"]) # <=== UPDATE
catalyst_data = get_catalyst_data(ticker_dict["ticker"]) # <=== UPDATE
results.append([
data["Ticker"],
format_number(data["Market Cap"]),
format_number(data["EV"]),
format_number(data["Cash"]),
f"{data['EV/Cash']:.2f}" if data["EV/Cash"] else "-",
catalyst_data # <== NEW FROM PART 1
])
headers = ["Tickers", "Market Cap", "EV", "Cash", "EV/Cash", "Num Catalysts"]
print(tabulate(results, headers=headers, tablefmt="pretty"))
Update our get_catalyst_data() function to get BPIQ Big Movers
- Now let's update our get_catalyst_data function to filter for BPIQ Big Movers and also return more catalyst data (not just the count).
def get_catalyst_data(ticker):
today = date.today()
months_to_add = 3
future_date = today + timedelta(days=months_to_add*30)
# call to bpiq api ==== NEW - ADDED &mover=true to end >>
url = f'https://api.bpiq.com/api/v1/drugs/?ticker={ticker}&catalyst_date_max={future_date}&mover=true'
headers = {
'Authorization': f'Token {credentials.BPIQ_API_KEY}'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
# ================ NEW ===============
catalyst_data = []
for result in data["results"]:
catalyst_data.append({
"drug_name": result["drug_name"],
"indication": result["indications_text"],
"catalyst_event": result["stage_event"]["label"],
"catalyst_date": result["catalyst_date_text"],
})
print(catalyst_data)
else:
print(f"Request failed with status code {response.status_code}")
return "-"
return catalyst_data # <==== UPDATED
We updated our BPIQ API call to filter for Big/Suspected Movers, and also return a list of dictionaries containing catalyst details like drug, indication, event details, and timing.
Update our main() function to write our data to a csv file
- We need to update our main function again, this time to write our data to a csv file. We will include the fundamental stock data and the catalyst data.
def main():
# with open("tickers.txt") as f:
# tickers = [line.strip().upper() for line in f if line.strip()]
# NEW ====
with open("tickers.csv", "r") as file:
# creates an iterable object with a dictionary for each row using the headers as the key
reader = csv.DictReader(file)
ticker_data_list = []
for row in reader:
ticker_data_list.append(row)
results = []
for ticker_dict in ticker_data_list: # <=== UPDATE
data = get_stock_data(ticker_dict["ticker"]) # <=== UPDATE
catalyst_data = get_catalyst_data(ticker_dict["ticker"]) # <=== UPDATE
results.append([
data["Ticker"],
format_number(data["Market Cap"]),
format_number(data["EV"]),
format_number(data["Cash"]),
f"{data['EV/Cash']:.2f}" if data["EV/Cash"] else "-",
catalyst_data
])
# ===== NEW ===
with open("catalyst_data.csv", "w", newline='') as outfile:
csv_writer = csv.writer(outfile, quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writerow(["Tickers", "Market Cap", "EV", "Cash", "EV/Cash", "Drug", "Indication", "Event", "Date"])
for result in results:
csv_writer.writerow([
result[0],
result[1],
result[2],
result[3],
result[4],
result[5][0].get("drug_name", ""),
result[5][0].get("indication", ""),
result[5][0].get("catalyst_event", ""),
result[5][0].get("catalyst_date", "")
])
# ==== OLD ===
# headers = ["Tickers", "Market Cap", "EV", "Cash", "EV/Cash", "Num Catalysts"]
# print(tabulate(results, headers=headers, tablefmt="pretty"))
We use python's built-in csv module again to write our data to a csv file. We add the stock data and then the first Big Mover Catalyst event for each ticker if they have one.
If you run the program you should see a new file "catalyst_data.csv". Open it in Excel and you should see all the data! Final GitHub Repo.